Lab 3: High-Level Synthesis
This lab introduces High-Level Synthesis (HLS).
You will implement a matrix-multiply kernel in HLS and offload computation to the FPGA.
Learning Objectives
- Understand the HLS design flow and how to write C++ code for hardware synthesis.
- Learn how to optimize HLS code for performance using techniques like pipelining and tiling.
- Gain experience with interfacing HLS kernels with software running on an embedded processor.
Recap
In the previous lab, we implemented matrix-multiply kernels in C and implemented optimizations to improve performance on a CPU. We started with a naive implementation and then applied optimizations to improve cache performance. We ended with a tiled kernel that did not perform well on in a single-threaded application on the CPU but was designed to be more amenable to hardware acceleration. By the end of this lab, we will have taken that tiled kernel and implemented it in HLS to run on an FPGA.
Baseline HLS Implementation
For the most part, HLS code looks like regular C++. However, there are some important differences and additional directives that we need to use to guide the synthesis process. Canonically, HLS is a subset of C++ that is designed to be synthesized into hardware. Some C++ features (e.g., dynamic memory allocation, virtual functions, etc.) cannot be used in HLS code. That means malloc, new, delete, and other dynamic memory management functions are not available. Additionally, HLS does not support vectors, maps, and other STL containers. Buffers can be allocated as C-style arrays or as local variables within the kernel function. The HLS compiler will analyze the code and determine how to map it to RTL logic which can be synthesized into hardware.
We’ll start with a simple, baseline implementation of matrix multiplication in HLS. This implementation will be straightforward without deliberate optimizations. The goal is to get a working kernel that we can compare against our optimized CPU implementation before we move on to the tiled version.
HLS Pragmas:
HLS PIPELINE II = 1
HLS pragmas are special directives that we can use in our C++ code to provide hints to the HLS compiler about how to generate and/or optimize the generated hardware.
For example, we can use
#pragma HLS PIPELINEto overlap the execution of subsequent loop iterations. This reduces the Initiation Interval (II), the number of clock cycles between starting new iterations, thereby increasing throughput. While the latency of a single iteration (the total cycles from start to finish) remains largely the same, the overall execution time is significantly improved because multiple iterations are processed in different stages of the pipeline sequentially.
II = 1means that a new iteration can start every clock cycle, which is ideal for maximizing performance.II = 2means that a new iteration can start every other clock cycle, and so on. The lower the II, the better the performance, as it allows for greater throughput. The HLS compiler will attempt to achieve the specified II, but it may not always be possible due to data dependencies or resource constraints. In such cases, the compiler will provide feedback on why the desired II could not be achieved, allowing developers to adjust their code or pragmas accordingly.
#include <ap_int.h>
template <typename T>
void matmul_core(
const T *A, // Read-only pointer to Matrix A
const T *B, // Read-only pointer to Matrix B
T *C, // Write-only pointer to Matrix C
const int N // Dimension (Assuming NxN)
) {
row_loop: for (int i = 0; i < N; i++) {
col_loop: for (int j = 0; j < N; j++) {
// We must use a local accumulator to avoid constant DDR writes for 'C'
// intermediate results.
T sum = 0;
dot_product_loop: for (int k = 0; k < N; k++) {
#pragma HLS PIPELINE II = 1
// This is a performance bottleneck:
// - Every iteration triggers two separate DDR read requests.
sum += A[i * N + k] * B[k * N + j];
}
// Write the final result for this element back to DDR
C[i * N + j] = sum;
}
}
}
extern "C" {
void matmul_kernel(
const int *A, // Read-only pointer to Matrix A
const int *B, // Read-only pointer to Matrix B
int *C, // Write-only pointer to Matrix C
const int N // Dimension (Assuming NxN))
) {
// - HLS INTERFACE directives specify how function arguments are mapped to
// hardware interfaces.
// - Here, we define an AXI4-Lite called interface called "control" for
// control signals (e.g., passing pointers and dimensions)
// - AXI4-Lite is a simple, low-bandwidth interface that supports single-beat
// transactions.
#pragma HLS INTERFACE s_axilite port=A bundle=control
#pragma HLS INTERFACE s_axilite port=B bundle=control
#pragma HLS INTERFACE s_axilite port=C bundle=control
#pragma HLS INTERFACE s_axilite port=N bundle=control
#pragma HLS INTERFACE s_axilite port=return bundle=control
// - We also define AXI4 master interfaces for the data channels, which allow
// the kernel to read and write data from/to DDR memory. Each channel is
// assigned to a separate memory interface (gmem0, gmem1, gmem2) to enable
// concurrent access.
// - The "offset=slave" attribute indicates that the base address for the
// memory pointer is provided as an argument via the AXI4-Lite
// control interface (slave port).
#pragma HLS INTERFACE m_axi port=A offset=slave bundle=gmem0 depth=1024
#pragma HLS INTERFACE m_axi port=B offset=slave bundle=gmem1 depth=1024
#pragma HLS INTERFACE m_axi port=C offset=slave bundle=gmem2 depth=1024
matmul_core<int>(A, B, C, N);
}
} // extern "C"
Tiled HLS Implementation
Now let’s implement the tiled version of matrix multiplication in HLS. To optimize our matrix multiplication kernel, we implement tiling (or blocking), a technique that decomposes high-dimensional iteration spaces into smaller blocks. Our initial baseline was bottlenecked by a low arithmetic-intensity. Because each Multiply-Accumulate (MAC) operation required a discrete, non-burst DDR read, the memory bus remained under-utilized while the FPGA’s DSP slices sat idle, waiting for individual data requests to complete. The tiled architecture mitigates this by leveraging burst-mode transactions to move data into On-Chip Memory (BRAM). By implementing tiling and burst-reads, we group the DDR requests into large contiguous blocks. This allows the memory controller to saturate the available bandwidth of the AXI bus, filling local BRAM buffers at the maximum possible rate and ensuring the DSP slices have a constant stream of data to process. See Roofline Model.
HLS Pragmas:
HLS ARRAY_PARTITION
- The
HLS ARRAY_PARTITIONpragma is used to partition arrays in HLS code, which can help improve performance by enabling parallel access to array elements. When an array is partitioned, it is divided into smaller sub-arrays that can be accessed independently, allowing for more efficient use of hardware resources and increased parallelism.- For example,
#pragma HLS ARRAY_PARTITION variable=A_tile complete dim=2would partition theA_tilearray completely along the second dimension (columns), allowing for parallel access to each column of the tile. This can be particularly beneficial in matrix multiplication, where we often want to access multiple elements of a row or column simultaneously.- The HLS compiler will attempt to partition the array as specified. Properly partitioning arrays can lead to significant performance improvements by enabling more parallelism and reducing access latency.
HLS UNROLL
- The
HLS UNROLLpragma is used to unroll loops in HLS code, which can help improve performance by allowing multiple iterations of the loop to be executed in parallel. When a loop is unrolled, the iterations are expanded into separate statements, enabling the HLS compiler to schedule them concurrently.- For example,
#pragma HLS UNROLLinside a loop would unroll the loop completely, meaning that all iterations would be executed in parallel. This can be particularly beneficial in matrix multiplication, where we often want to perform multiple operations on different elements of the matrices simultaneously.- The HLS compiler will attempt to unroll the loop as specified. Properly unrolling loops can lead to significant performance improvements by enabling more parallelism and reducing the number of clock cycles needed to execute the loop.
In our tiled matrix multiplication implementation, we will use both
HLS ARRAY_PARTITIONto enable parallel access to the tiles of the matrices andHLS UNROLLto allow for concurrent execution of operations within the innermost loop. This combination will help us maximize the performance of our HLS kernel by fully utilizing the FPGA’s resources. The HLS compiler will attempt to apply these optimizations, but the actual partition and unrolling may depend on the specific dimensions of the tiles and the available hardware resources.
#include <ap_int.h>
#include <algorithm>
#include <cstring>
template <typename T, int TILE_SIZE = 32>
void tiled_matmul_core(const T *A, const T *B, T *C, int N)
{
T A_tile[TILE_SIZE][TILE_SIZE];
T B_tile[TILE_SIZE][TILE_SIZE];
T C_tile[TILE_SIZE][TILE_SIZE];
#pragma HLS ARRAY_PARTITION variable = A_tile complete dim = 2
#pragma HLS ARRAY_PARTITION variable = B_tile complete dim = 1
block_row_loop: for (int i_t = 0; i_t < N; i_t += TILE_SIZE) {
block_col_loop: for (int j_t = 0; j_t < N; j_t += TILE_SIZE) {
// Clear local C tile
init_c_tile: for (int i = 0; i < TILE_SIZE; i++)
for (int j = 0; j < TILE_SIZE; j++)
#pragma HLS PIPELINE II = 1
C_tile[i][j] = 0;
block_k_loop: for (int k_t = 0; k_t < N; k_t += TILE_SIZE) {
int rows = std::min(TILE_SIZE, N - i_t);
int cols = std::min(TILE_SIZE, N - j_t);
int depth = std::min(TILE_SIZE, N - k_t);
// Load A and B with row-bursts
load_a_tile: for (int r = 0; r < rows; r++)
std::memcpy(A_tile[r], &A[(i_t + r) * N + k_t], depth * sizeof(T));
load_b_tile: for (int r = 0; r < depth; r++)
std::memcpy(B_tile[r], &B[(k_t + r) * N + j_t], cols * sizeof(T));
// Compute
compute_tile: for (int k = 0; k < depth; k++) {
for (int i = 0; i < rows; i++) {
#pragma HLS PIPELINE II = 1
for (int j = 0; j < cols; j++) {
#pragma HLS UNROLL
C_tile[i][j] += A_tile[i][k] * B_tile[k][j];
}
}
}
}
// Store results
store_c_tile: for (int r = 0; r < std::min(TILE_SIZE, N - i_t); r++)
std::memcpy(&C[(i_t + r) * N + j_t], C_tile[r],
std::min(TILE_SIZE, N - j_t) * sizeof(T));
}
}
}
extern "C"
{
void tiled_matmul_kernel(
const int *A, // Read-only pointer to Matrix A
const int *B, // Read-only pointer to Matrix B
int *C, // Write-only pointer to Matrix C
const int N // Dimension (Assuming NxN)
) {
#pragma HLS INTERFACE s_axilite port=A bundle=control
#pragma HLS INTERFACE s_axilite port=B bundle=control
#pragma HLS INTERFACE s_axilite port=C bundle=control
#pragma HLS INTERFACE s_axilite port=N bundle=control
#pragma HLS INTERFACE s_axilite port=return bundle=control
#pragma HLS INTERFACE m_axi port=A offset=slave bundle=gmem0 depth=1024
#pragma HLS INTERFACE m_axi port=B offset=slave bundle=gmem1 depth=1024
#pragma HLS INTERFACE m_axi port=C offset=slave bundle=gmem2 depth=1024
constexpr int tileSize = 128;
tiled_matmul_core<int, tileSize>(A, B, C, N);
}
}
Evaluating
Once we have our HLS kernels implemented, we can evaluate their performance against our best performing CPU implementation. When the kernel is packaged into an IP block and integrated into a hardware design, the HLS tool will generate a header file (e.g., xmatmul_kernel.h) that provides an API for interfacing with the kernel from software. The code below demonstrates how to use this API to run the kernel on the FPGA.
#include "xil_cache.h"
#include "xil_printf.h"
#include "xmatmul_kernel.h" // Header generated by HLS tool for our kernel
static XMatmul_kernel accelerator;
static constexpr int N = 4;
static constexpr int SIZE = N * N;
static int A[SIZE] __attribute__((aligned(64)));
static int B[SIZE] __attribute__((aligned(64)));
static int C_hw[SIZE] __attribute__((aligned(64)));
static int C_sw[SIZE] __attribute__((aligned(64)));
void run_matmul_kernel(int *a_ptr, int *b_ptr, int *c_ptr, int n) {
XMatmul_kernel_Initialize(&accelerator, XPAR_XMATMUL_KERNEL_0_BASEADDR);
XMatmul_kernel_Set_A(&accelerator, (UINTPTR)a_ptr);
XMatmul_kernel_Set_B(&accelerator, (UINTPTR)b_ptr);
XMatmul_kernel_Set_C(&accelerator, (UINTPTR)c_ptr);
XMatmul_kernel_Set_N(&accelerator, n);
Xil_DCacheFlushRange((UINTPTR)a_ptr, n * n * sizeof(int));
Xil_DCacheFlushRange((UINTPTR)b_ptr, n * n * sizeof(int));
Xil_DCacheFlushRange((UINTPTR)c_ptr, n * n * sizeof(int));
XMatmul_kernel_Start(&accelerator);
while (!XMatmul_kernel_IsDone(&accelerator)) {}
Xil_DCacheInvalidateRange((UINTPTR)c_ptr, n * n * sizeof(int));
}
Below is the same code for the tiled kernel:
#include "xil_cache.h"
#include "xil_printf.h"
#include "xparameters.h"
#include "xtiled_matmul_kernel.h" // Header generated by HLS tool for our kernel
static XTiled_matmul_kernel accel;
void run_tiled_matmul_kernel(int *a_ptr, int *b_ptr, int *c_ptr, int n) {
XTiled_matmul_kernel_Initialize(&accel, XPAR_XTILED_MATMUL_KERNEL_0_BASEADDR);
// ...
}
Tutorials
Creating an HLS Component in Vitis
This guide assemus you’re working with Vitis 2025.2 or later. Older versions of Vitis distinguished between “Vitis HLS” for HLS development and “Vitis” for software development. In Vitis 2025.2, these tools have been unified into a single Vitis IDE that supports both hardware and software development. The steps outlined below are based on the unified Vitis IDE, so if you’re using an older version, you may need to adapt the instructions accordingly.
- Creating the HLS Project
- Open Vitis IDE and open your workspace from previous labs.
- In the application menu, select
File > New Component > HLS. - In the “Create HLS Component” dialog, enter a name for your component (e.g.,
matmul_kernel), and select Next. - Configuration File:
- Select the default option “Empty File”,
- Enter a configuration name (e.g.,
hls_config).
- Source Files:
- We don’t have any source files yet, so just click Next.
- Hardware:
- Use part number
xczu3eg-sfvc784-2-e, which corresponds to the Zynq Ultrascale+ MPSoC on the AUP-ZU3 board, and click Next.
- Use part number
- Settings:
- Set target clock to
5ns(200 MHz) and click Next. - Leave clock uncertainty blank and click Next.
- Set target clock to
- Summary:
- Review the summary and click Finish to create the HLS component.
- Implementing the HLS Kernel
- In the Project Explorer, navigate to the
Sourcesfolder of your newly created HLS component. - Right-click on the
Sourcesfolder and selectNew Source File. - Name the file
matmul_kernel.cppand click Finish. - Open
matmul_kernel.cppand implement the matrix multiplication kernel as shown in the code snippet above.
- In the Project Explorer, navigate to the
- Testing the HLS Kernel
- To test your HLS kernel, you can create a testbench in C++ that calls the kernel function with sample input data and checks the output against expected results.
- Navigate to the
Testbenchesfolder in your HLS component, right-click, and selectNew Test Bench File. - Name the file
matmul_testbench.cppand click Finish. - Open
matmul_testbench.cppand implement a testbench that initializes input matrices, calls thematmul_kernelfunction, and verifies the output. Below is a simple example of how you might structure your testbench:
// Example starter testbench for matmul_kernel: // - Missing reference implementation and verification code, // but this is where you would implement those. #include <cstdlib> #include <iostream> extern "C" { void matmul_kernel(const int *A, const int *B, int *C, int N); } int main() { const int N = 4; int A[N * N] = { /* Initialize with test data */ }; int B[N * N] = { /* Initialize with test data */ }; int C[N * N] = {0}; matmul_kernel(A, B, C, N); // Verify results in C against expected output // ... return EXIT_SUCCESS; } - Synthesizing and Packaging the HLS Kernel
- In the Flow Panel, run C Simulation, C Synthesis, and C/RTL Co-Simulation to verify the functionality of your HLS kernel and to analyze its performance.
- After successful synthesis, you can review the performance reports to see metrics such as latency, initiation interval, and resource utilization. This information can help you identify bottlenecks and guide further optimizations.
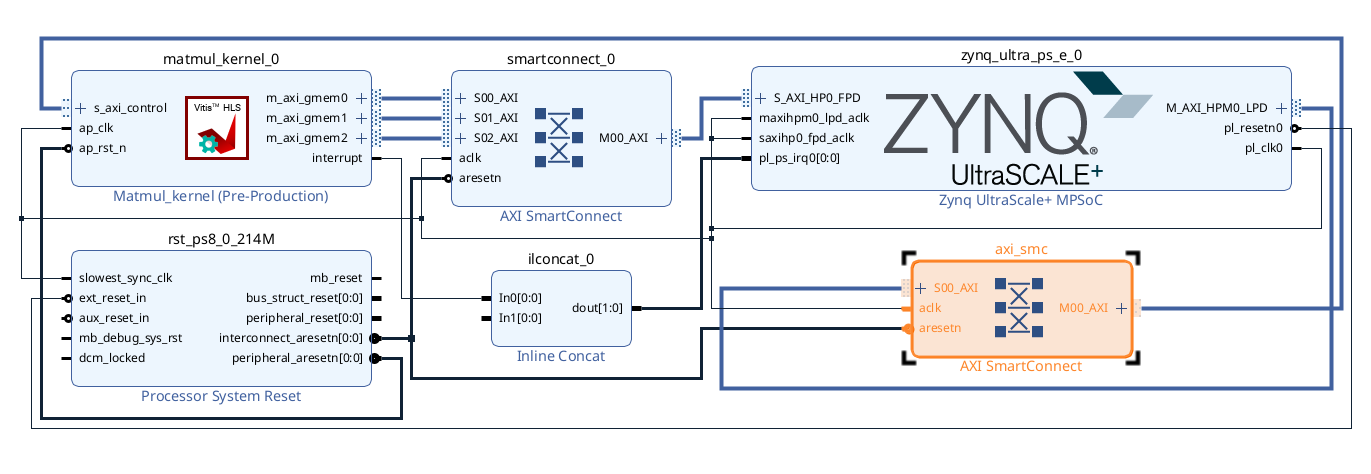
- Once you are satisfied with the performance of your HLS kernel, you can proceed to package it as an IP block and integrate it into a hardware design using Vivado IP Integrator. To do so, run “PACKAGE” from the Flow panel, which will package your HLS kernel into an IP block that can be imported into Vivado.
Synthesis Flow:
- C Simulation will run your testbench in a software environment
- C Synthesis will generate the hardware description and provide performance estimates.
- C/RTL Co-Simulation allows you to simulate the synthesized RTL code alongside your testbench to ensure that the generated hardware behaves as expected.
Integrating HLS IP in Vivado IP Integrator